利用Huginn抓取任意网站RSS和微信公众号更新-打造一站式信息阅读平台
Huginn其实非常适合像我这样的RSS阅读重度“用户”。很多RSS阅读器因为赚不到钱逐渐被公司所抛弃——商人嘛,无利可图自然不可持久。同时,一些新闻资讯类的网站也讨厌RSS,因为RSS用户对于他们来说不会带来流量——没有流量,自然没有收入。
目前来看,RSS的地位非常地“尴尬”,它在RSS开发者和RSS内容输出者面前非常不受欢迎,甚至有极端者“恨不得RSS已死”。幸好,RSS还有一大批忠实用户,一直支撑着RSS的发展,即便是移动APP的出现,也未能直接将RSS判定为“死亡”。
另外,对于微信公众号重度“患者”Huginn也有很好的“药方”。利用搜狐微信平台,Huginn可以帮助我们定时抓取微信公众号的文章更新,然后生成RSS,你可以将所有的公众号文章聚合到一个平台。Huginn可以为你抓取RSS全文,从此解放你的双手。
Huginn还可以监控天气预报,如果明天下雨,则给你发送提醒;监控某款商品的网页,一旦降价,通知你;监控某款商品的网页,一旦降价,通知你……官方还有非常多的应用实例,网友们也写出了非常多的Huginn脚本,帮助你打造一个只属于自己的IFTTT服务。
有人说,在某种程度上讲,Huginn比IFTTT还强大,因为Huginn可以与Slack、Pushbullet等进行整合,这样无论在身处何地何时,你都可以通过手机接收到Huginn给抓取的网站RSS更新、微信公众号文章、天气提醒、行程安排、待办事项、新闻动态……

- 三大免费工具助你检测VPS服务器真伪-VPS主机性能和速度测试方法
- Lsyncd搭建同步镜像-用Lsyncd实现本地和远程服务器之间实时同步
- 新版BT.cn宝塔VPS主机面板建站使用体验-清爽傻瓜式操作功能全面
PS:2017年10月31日更新,感觉Huginn麻烦的朋友,可以试试这一款免费的在线抓取全文RSS工具:生成和订阅任意网站RSS工具-实现RSS全文,邮箱和手机APP提醒。
一、Huginn安装部署方法
Huginn安装部署官网推荐有两种方式,一种是将Huginn安装部署在自己的VPS主机上,过程比较繁琐,但是成功率还是非常高,这主要归功于Huginn官网的教程已经做到了傻瓜式。另一种则是部署在Heroku平台,免费的,适合没有自己的服务器的朋友。
1.1 VPS部署Huginn
Huginn部署VPS主机支持Ubuntu (16.04, 14.04 and 12.04)和Debian (Jessie and Wheezy),你只要按照官网的教程一步一步地复制执行命令,基本上可以成功了:Huginn在Debian/Ubuntu手动安装教程-抓取全文RSS和微信公众号开源软件。
1.2 Heroku部署Huginn
需要的东西
- Codeanywhere 账号:https://codeanywhere.com/
- Heroku 账号:http://herokuapp.com/
部署步骤
登陆 Huginn Github 主页的 Deployment 部分:https://github.com/huginn/huginn#deployment,找到 Heroku 的按钮。然后点击,就会跳转到你的 Heroku 了。
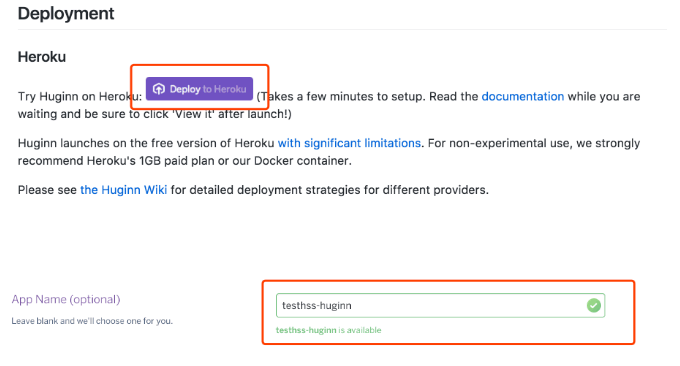
点完按钮之后会跳转到你的 Heroku 界面去起个名字。直接拉到最后点 Deploy 的按钮,之后它就会开始 build 了。
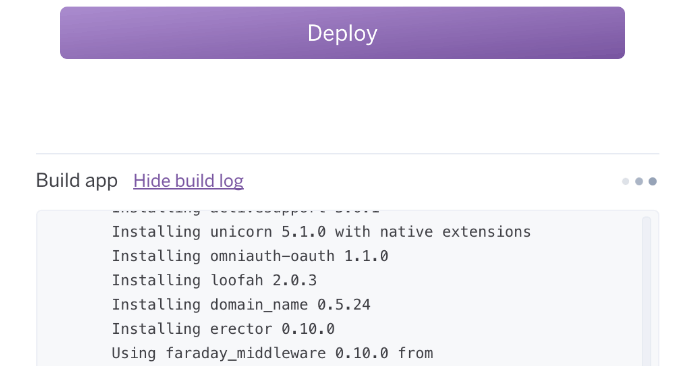
创建好了后,点击 View 就直接跳转到已经建立好的应用了。Manage App 会跳转到 Heroku 管理界面。点击 View后可以看到 Huginn 很人性化的把步骤贴出来了。由于我们用的是自动安装,所以没有创建管理员用户,也有一些东西需要配置。(可以看到已经可以访问域名了)
现在我们对照着 Huginn 的说明来做。登陆 Codeanywhere,点击右上角的 Editor。会进入一个选择界面,如截图。
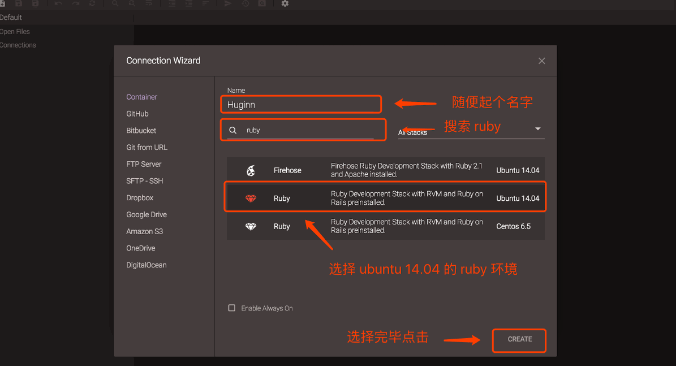
第一次的话点完 Create 会让你验证邮箱,验证完邮箱对着上图再做一遍就可以了。我们首先要下载新版本的 ruby 环境。
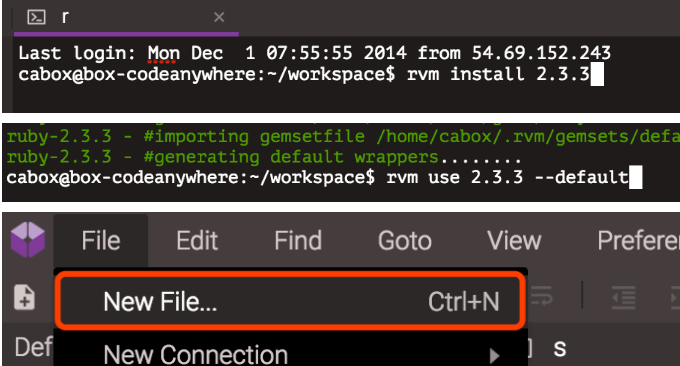
打开huginn.sh:https://github.com/tesths/tesths.github.com/blob/master/images/huginn/huginn.sh,复制到 Codeanywhere 的文件编辑器里。然后点击右上角保存。保存到根目录下,文件名保存为 huginn.sh。
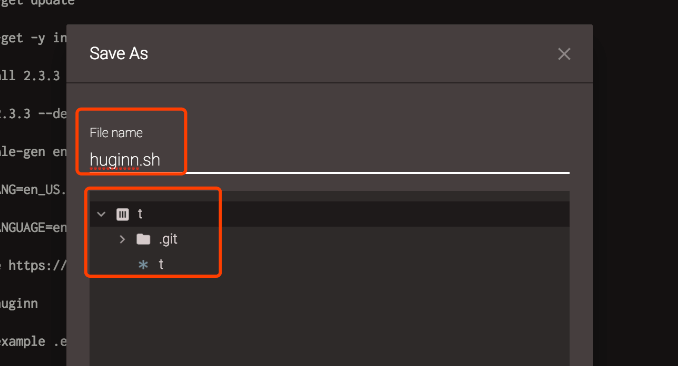
然后在你的 Heroku 界面找到下图的地方,在以下地方将code-huginn换成你自己的名字。(点击放大)
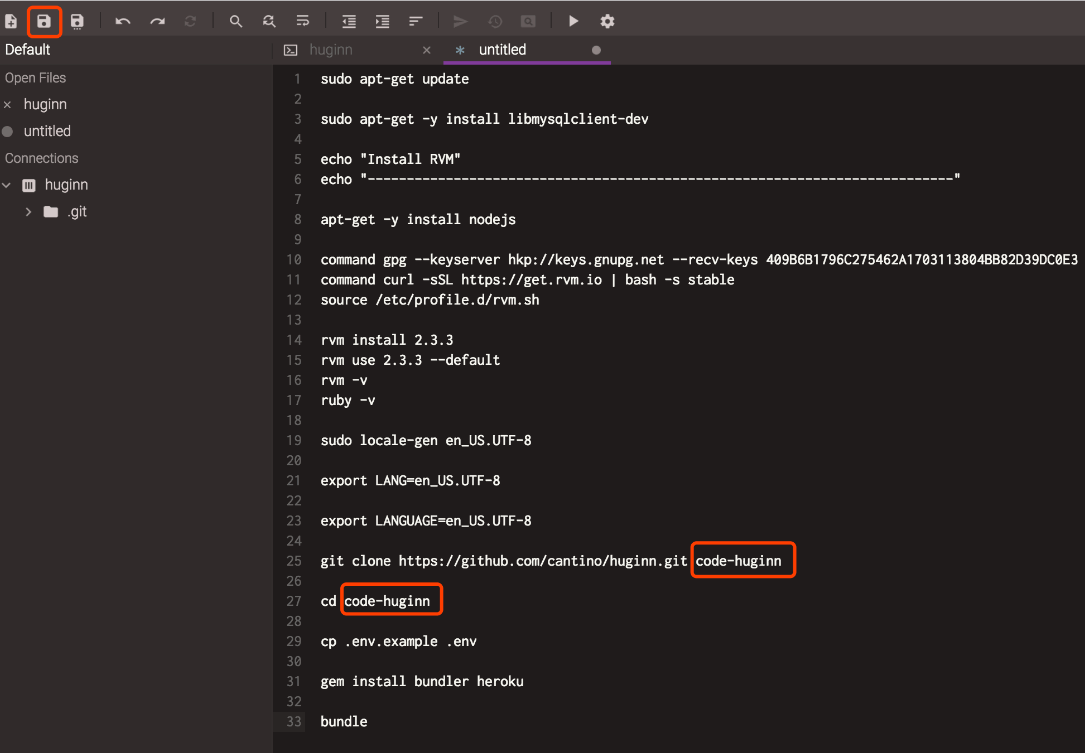
然后执行脚本 huginn.sh,命令:bash huginn.sh。执行完毕之后,进行如下操作即可:
- 先进入
cd code-huginn/(这里的 code-huginn 输入你刚替换的名字就好)。 - 在命令行登陆你的 heroku ,就是在命令行输入
heroku login。 - 之后执行
heroku git:remote -a code-huginn。 - 最后执行
bin/setup_heroku。剩下的就是开始自动配置了。
heroku空间几点说明:
- heroku免费账户的网站在30分钟内无人访问后会自动关闭(休眠),可以使用网站监控服务来防止其休眠,例如:uptimerobot:https://uptimerobot.com。
- heroku免费用户的所有app运行总时长为每个月550小时,也就是说你的APP无法保证30X24X7小时全天候运行,建议让网站每天只运行18小时。当然添加信用卡之后,会再赠送450小时。
- heroku免费账户只有5M的 Postgres 数据库,只允许在数据库中记录10000行,因此,作者建议设置
heroku config:set AGENT_LOG_LENGTH=20。 - Huginn安装在heroku的过程中默认使用的是SendGrid的邮箱服务器,但是heroku非信用卡用户无法使用SendGrid的邮箱服务器,建议添加其它邮箱服务器,比如,gmail邮箱服务器,具体设置如下:
heroku config:set SMTP_DOMAIN=google.com heroku config:set SMTP_USER_NAME=<你的gmail邮箱地址> heroku config:set SMTP_PASSWORD=<邮箱密码> heroku config:set SMTP_SERVER=smtp.gmail.com heroku config:set EMAIL_FROM_ADDRESS=<你的gmail邮箱地址>
二、Huginn抓取任意网站RSS并输出全文
2.1 抓取文章RSS
进入到Huginn,点击新建Agent,类型选择Website Agent,名字随便取,其它的保持默认。
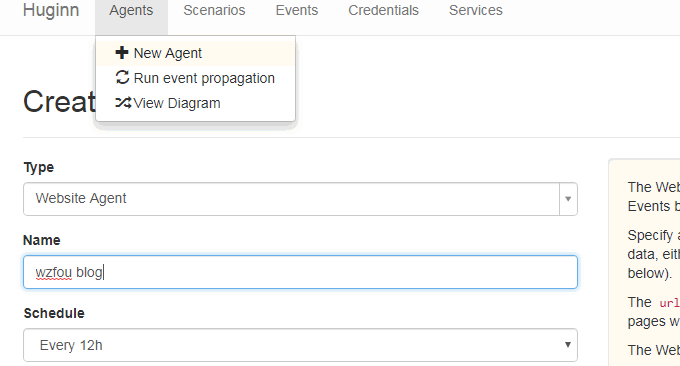
填写选项内容。在选项中就是我们填写抓取规则的地方了。
- url填入需要解析的页面,例如:wzfou.com
- type表示格式,可以有html, xml, json, text多种格式
- mode表示信息的输出处理方式,“on_change”表示仅输出下面的内容,”merge”表示新内容和输入的agent内容合并。
- extract是我们要提取的信息。
extract内容。主要就是标题、链接、内容和时间等,我们只需要填写相关内容的Xpath路径,另外对于链接的话加入值:value: @href,标题加入:value: normalize-space(.)。如下图:(点击放大)

关于获取网页的Xpath的方法,直接使用Chrome,右击我们要获取的内容,然后选择“审查元素”,再到控制面板右击,选择复制Xpath。例如wzfou.com的最新文章的url的Xpath是://*[@id=”cat_all”]/div/div/div[2]/div/h2/span/a。
另外,由于我们获取到的Xpath往往是某一个具体的元素的,想要匹配所有的符合要求的元素,我们还可以借助Chrome的Xpath插件:XPath Helper。例如我们获取一般是://*[@id=”cat_all”]/div[1]/div/div[2]/div/h2/span/a。通过插件我们测试出去年第一个divr的1,也就是变成我上面的://*[@id=”cat_all”]/div/div/div[2]/div/h2/span/a。于就匹配了所有的最新文章链接地址了。
其它的标题、内容、时间等都可以参考上面的方法获取到。

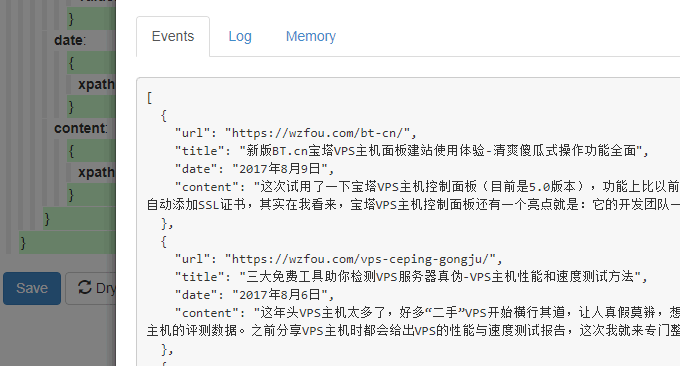
预览抓取结果。点击“Dry Run”,你就可以预览抓取结果了。注意到“事件”中看到抓取了结果,就表示该Website Agent设置成功了。
2.2 获取RSS全文
还是点击新建Agent,类型选择Website Agent,来源选择你刚刚创建的Website Agent。
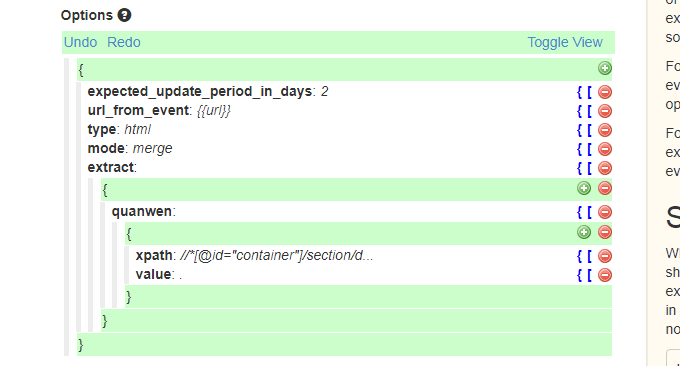
然后在选项设置处,URL填写:{{url}},即抓取你刚刚获取RSS的链接地址,mode选择“merge”,xpath就是本文的Xpath,value填入“.”,即原样输出全文并合并原先的输出。
2.3 生成RSS地址
点击新建Agent,类型选择Data Output Agent,Sources中填入第二步的Agent名称。

在选项中填入你的RSS的标题、描述、链接等信息,同时在Item中填写标题、描述、链接等,即输出RSS全文的标题、内容与链接地址等等。
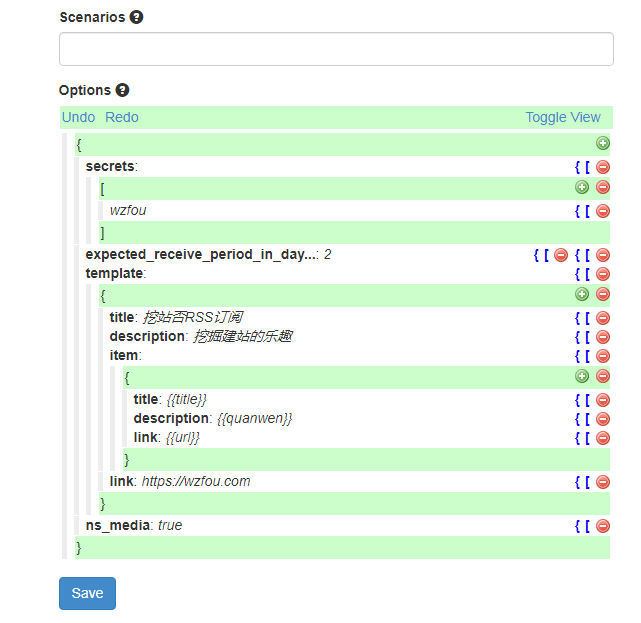
最后,你就可以看到RSS订阅地址已经生成的。
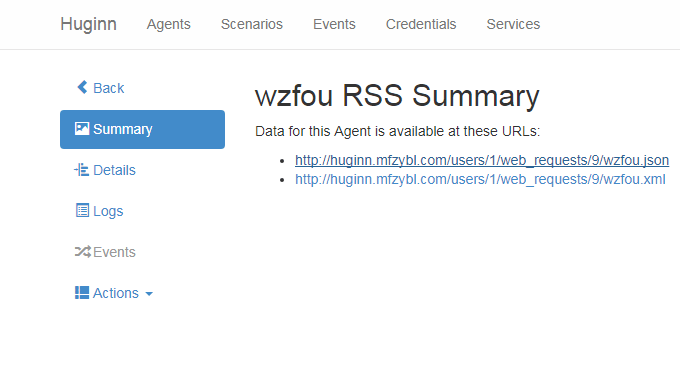
复制该RSS订阅地址到RSS阅读器,就可以订阅文章更新了。
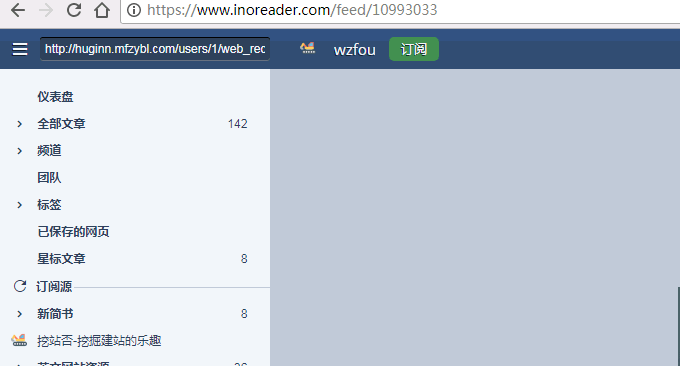
如果你没有RSS输出,请检查以下三点:
- WebsiteAgent接受到的Event,是否有url这个字段?
- 如果event里url字段,用 url_from_event 就行了
- dry run 时会提示你输入Event作为输入,这是要输入一个带url的event,否则当然没输出了。
三、Huginn抓取微信公众号并输出RSS
抓取微信公众号的文章更新,首先需要一个网页。这里我们需要利用的就是搜索微信平台了,例如挖站否的微信是这样的:
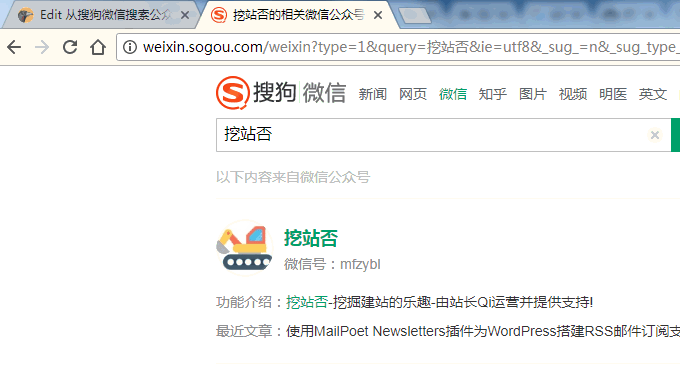
原理还是和上面一样的,创建Website Agent,去抓取搜狐微信页面,通过Xpath获得“最近文章”内容,然后得到最近文章的URL,继续抓取,最终获得微信公众号文章全文。
这里有一个抓取微信公众号生成RSS输出的scenarios,你可以直接下载导入:https://www.ucblog.net/wzfou/weixin.json。
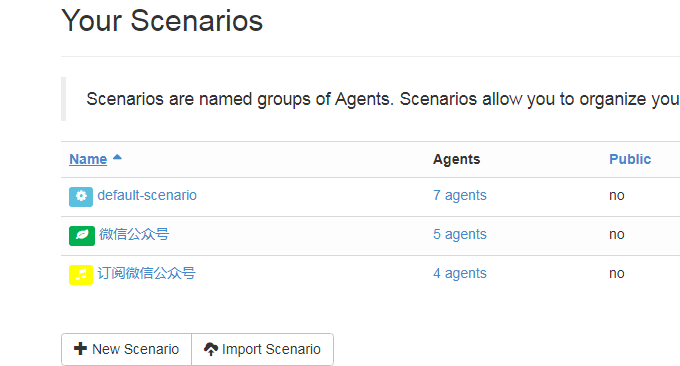
导入完成后,你只需要修改“从搜狗微信搜索公众号,获取最新文章标题”和“获取公众号最新文章的链接地址”两个Agent的URL,换成你想要订阅的微信公众号URL即可。

最后,确保所有的Agent正常运行。
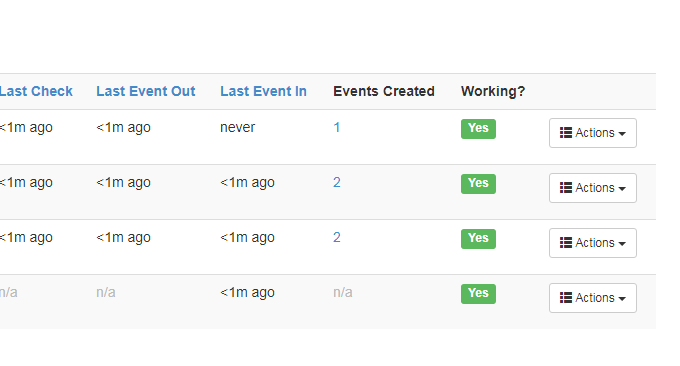
然后,你就可以使用RSS阅读器订阅微信公众号更新了。

四、Huginn一站式信息阅读
PC电脑端。自然是用RSS阅读器了,不管你是用RSS订阅软件,还是使用RSS在线订阅平台,你只要有一个RSS订阅源,你可以享受在任意电脑上查看自己的RSS信息了。国内的可用一览(目前有 100 个订阅数的限制),国外用Inoreader(无限制但有广告)。

手机移动端。手机上可以安装RSS阅读器的APP,但是更强大的是Huginn可以结合IFTTT、Pushbullet、Slack等将图片、超链接、文件、文字等内容发到你自己的手机上,或者直接发到你的微信、QQ、邮箱等。
五、总结
Huginn可以订阅任意你想要订阅的网站与平台,例如微信公众号、简书、知乎、博客、图虫、Lofter……,只要有网页同时生成了CSS,你就可以派出你的“Agent”去把他们抓回来,然后将他们“分门别类”,任意处置了。
看完此文的朋友,一定知道Huginn的门槛就在于环境的部署以及Website Agent规则的制定。虽然说Huginn有scenarios可供导入导出,但是目前为止还没有一个像油猴那样大规模的scenarios库,所以Huginn普及是非常困难的。
目前,大家可以在这里找到几个可供使用的脚本库:http://huginnio.herokuapp.com/scenarios。另外,Heroku部署Huginn也不是长久之计,一是Heroku基本上打不开,二来免费服务还不能运行24小时,不差钱的朋友可以购买一个VPS主机部署Huginn。这是我用过的VPS:VPS主机排行榜单。
文章出自:挖站否 https://wzfou.com/huginn-rss/,部分内容参考自walkginkgo、xzonepiece、walkginkgo、pmvince 版权所有。本站文章除注明出处外,皆为作者原创文章,可自由引用,但请注明来源。






关于站长(Qi),2008年开始混迹于免费资源圈中,有幸结识了不少的草根站长。之后自己摸爬滚打潜心学习Web服务器、VPS、域名等,兴趣广泛,杂而不精,但愿将自己经验与心得分享出来与大家共勉。




猜你喜欢




-

Qi 大,我想监#控某个公众号发布新文章提醒,实时收到推送通知提醒,然后自己再去该公众号打开查看。不知道现在有没有办法可以监控公号文章更新的 ? 求推荐。教程上提到的搜狐微信平台已经没法用了
谢谢🙏2020年9月9日 18:11-

目前来看,可能不好搞,主要是因为微信封得厉害,用爬虫都不行。
2020年9月9日 18:59
-
-

几个agent的working一直“No”;点击run,Last Erro:Broken pipe @ io_writev – /app/app/models/agent_log.rb:16:in `write’,同样的问题,怎么解决,求博主细说,谢谢。
2020年2月20日 23:13-
貌似是编码问题:https://github.com/huginn/huginn/issues/1514
2020年2月20日 23:25-

我在阿里云上用docker部署的huginn。我也出现了这个问题,需要重新登陆终端,docker关闭再开启higinn容器,再登陆huginn,运行才能正常。我看也有其他人也遇到了这个问题,他是在腾讯云上挂的huginn,关闭终端或者长时间连接自动关闭后,也会出现broken pipe的问题,也是关闭容器再重启变好的。
2021年6月8日 10:30
-
-
-

working一直“No”;点击run,Last Erro:Broken pipe @ io_writev – /app/app/models/agent_log.rb:16:in `write’
2020年1月29日 20:21-
规则错误,需要纠正一下。
2020年2月3日 10:24-
已经可以了,谢谢。
2020年2月7日 00:48-
请问怎么解决的啊 我也遇到这个问题了
2021年6月5日 15:25-
可以了,这个问题挺常见,留下给后边的人提供一个思路。我在阿里云上用docker部署的huginn。我也出现了这个问题,需要重新登陆终端,docker关闭再开启higinn容器,再登陆huginn,运行才能正常。我看也有其他人也遇到了这个问题,他是在腾讯云上挂的huginn,关闭终端或者长时间连接自动关闭后,也会出现broken pipe的问题,也是关闭容器再重启变好的。
2021年6月8日 10:31
-
-
-
-
-

请教下,输出全文那个website agent 如何调试?运行dry run,得到的结果是空。博主能否把agent原始的option发出来参考下,谢谢。
2019年3月31日 08:14-
已搞定,需要点击下上个一website agents获取到的event列表中的任意一个envent
2019年3月31日 15:43
-
-

抓取微信回来的文章图片是不是有问题?
2019年3月11日 12:10 -

请问…怎样设置能让网站只运行18个小时?可以设置起始时间吗?
2018年12月1日 17:15-
好像不行,得自己手动。
2018年12月1日 17:36
-
-

博主你好,如果一个有好几段文字复合要求想合并到1个event里面输出要怎么做啊?
2018年6月11日 22:44-
可以在mode中选择多个内容合并模式。
2018年6月19日 17:41
-
-

您好最后一步遇到这个问题该怎么解决呢,我把名字改成yui了
$ heroku git:remote -a code-huginn
This is the legacy Heroku CLI. Please install the new CLI from https://cli.heroku.com
▸ You do not have access to the app code-huginn.
cabox@box-codeanywhere:~/workspace/yui$ bin/setup_heroku
This is the legacy Heroku CLI. Please install the new CLI from https://cli.heroku.com
Welcome @gmail.com! It looks like you’re logged into Heroku.bin/setup_heroku:33:in `’: invalid byte sequence in US-ASCII (ArgumentError)
cabox@box-codeanywhere:~/workspace/yui$2018年6月10日 19:19-
看错误提示好像是组件没有安装好,你可能还需要安装CLI 这样的工具。
2018年6月19日 17:45
-
-
博主您好,我把code-huginn改成yui了,但是到了“之后执行 heroku git:remote -a code-huginn。”这一步就出现下面的错误提示,该怎么解决呢
cabox@box-codeanywhere:~/workspace/yui$ heroku git:remote -a yui
This is the legacy Heroku CLI. Please install the new CLI from https://cli.heroku.com
▸ You do not have access to the app yui.
cabox@box-codeanywhere:~/workspace/yui$ heroku git:remote -a code-huginn
This is the legacy Heroku CLI. Please install the new CLI from https://cli.heroku.com
▸ You do not have access to the app code-huginn.
cabox@box-codeanywhere:~/workspace/yui$ bin/setup_heroku
This is the legacy Heroku CLI. Please install the new CLI from https://cli.heroku.com
Welcome sczan110@gmail.com! It looks like you’re logged into Heroku.bin/setup_heroku:33:in `’: invalid byte sequence in US-ASCII (ArgumentError)
2018年6月10日 19:05 -

原创
李叫兽传:他打架、失业,却成为百度最年轻的副总裁
请问类似这样的网页源码,通过xpath获取的url只有artical/2004698而非正确的网页链接,请问应该怎样处理啊?2018年4月21日 00:13-
发现直接变成有格式的文字,emmm,附链接http://www.gzhshoulu.wang/account_U_quan.html
附图
求解惑2018年4月21日 00:20-
网页用的是相对文本,可以修改一下事件中url,让它默认抓取全部链接。
2018年4月21日 15:24-
应该怎么改啊😯完全小白,不懂…
2018年4月22日 11:18 -
多谢提点,解决了
2018年4月30日 09:34-
好的,不客气。
2018年4月30日 15:10
-
-
-

你好,请问你是怎么解决的呢?
2019年2月12日 19:08
-
-
-

你好,感谢分享
有个问题,我设置了heroku config:set AGENT_LOG_LENGTH=20,RSS用来抓取gaoqing.la的更新,前面设置都没问题dry
run也正常,但是最后RSS输出的时候却倒序输出了20个电影,请问该怎么解决2018年4月19日 11:24 -

不死心的再问一下😂😂,您说的是文章内显示图片有难度对吗?
2018年4月17日 12:36-
有些麻烦,因为图片不固定,所以不好用Xpath的方法来确定图片。
2018年4月18日 16:36-
谢谢站长^_^
2018年4月18日 22:54-
上一句没把字打完😂😂,谢谢站长回复
2018年4月18日 22:55
-
-
-
-
你好,我按照步骤操作后发现没有rss输出。再次阅读文章后发现只有这一步没操作过
“dry run 时会提示你输入Event作为输入,这是要输入一个带url的event,否则当然没输出了。”
这一步的具体操作是什么啊?有点懵。。这个图我在第二个rss中的options,这是我输出的rss链接https://g-rss.herokuapp.com/users/2/web_requests/13/kejimx.xml 麻烦大佬看一下原因
2018年4月11日 10:37-
代码没有问题,这段话的意思是要设置一个事件,否则就不会有结果。再检查一下xpath是不是有错误?
2018年4月11日 12:36-
我真的是黔驴技穷了😂😂能抽空帮忙看下这个文章的xpath吗?http://www.jintiankansha.me/t/yE0ihQXtjc 又试了几个还是没有输出
2018年4月11日 19:45-
我研究了一下,是想要这个页面的全部内容吗?还是第一步版块的内容?
2018年4月12日 14:47-
当时不知道为什么显示没有event,现在已经可以了,只是还不显示图片…
想要文章的文字和图片
我填的是//*[@id=”Main”]/div[2]/div[2]
按理说应该显示图片才对啊,您能帮忙看下可以显示图片的xpath吗?
还是说这个网站无法输出图片呢?
之前用feed43和feedex全文输出也是没有图片2018年4月14日 11:57-
图片貌似有难度,主要是文章的第一张图片不固定,有时是第一个,有时又跑到后面去了。
2018年4月16日 09:32-
谢谢回复
2018年4月16日 18:10
-
-
-
-
-
-
-

再打扰一下,在2.1那一步中我明明 就是按教程做的啊,为什么没有event输出呢😂😂
2018年4月4日 11:25-
那应该是Xpath没有正确填写好。
2018年4月5日 11:45-
谢谢
2018年4月7日 23:31
-
-
-
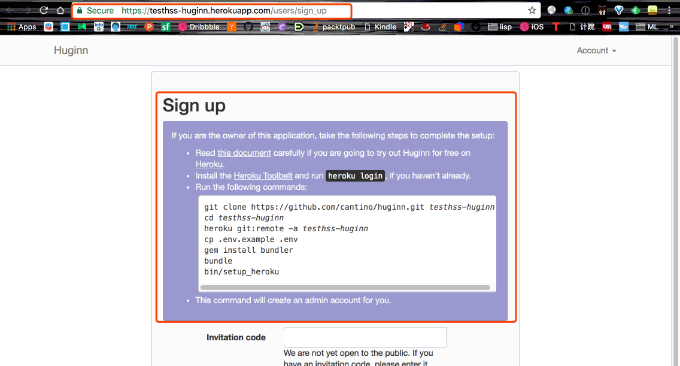
请问图三那里的invatation code怎么填啊
2018年4月1日 10:12-
这是哪里的?
2018年4月2日 17:43-
就是点击 open app 后点注册就这样了…想登录也没有找到账号
2018年4月2日 19:09-
默认的登录账号是:admin,密码是:password。不用注册。进入到Huginn修改密码即可。
2018年4月3日 13:52-
谢谢回复
2018年4月3日 20:21
-
-
-
-
-

好的,感谢楼主答复。
2018年3月2日 20:14 -
抓取微信公众号生成RSS输出的scenarios是否已经失效,我创建完无法获取文章了。
2018年2月27日 12:39-
应该是失效了,微信那边对这些爬取工具做了限制。
2018年2月28日 10:37-
感谢楼主回复,那现在还要啥办法获取微信公众号的RSS?
2018年3月2日 12:32-
微信封得有些厉害,目前恐怕只能自己写爬虫了。
2018年3月2日 20:13
-
-
-
-

您好,在2.2中, mode选择“merge”,xpath就是本文的Xpath,value填入“.” ,請問“本文的xpath”是什麽?
2018年2月17日 21:22-
就是用chrome获取到的xpath路径。
2018年2月21日 11:41
-
-
请问,在workspace里执行 bash huginn.sh 提示 没有 huginn.sh应该如何操作?
2018年2月17日 17:36-
.sh安裝在huginn的根目錄下。
2018年2月17日 21:22 -
huginn.sh下载并保存了吗?
2018年2月21日 11:43
-
-

尝试使用Huginn 的邮箱的时候,出现下面的错误
550 Unauthenticated senders not allowed
我查了一下,已经是用gmail邮箱的了,它还是有错误提示
请问,如何解决呢?谢谢2018年1月31日 21:22-
是Huginn提示这样的错误吗?
2018年2月2日 10:39
-
-
你好, 求教一下
我尝试做全文RSS输出,但是全文website agent 在 dry run 的时候没有输出结果dry run 的时候,上面已经出现了 {url: xxx, title:xxx}的event data, 说明source的那个website agent已经抓取到东西了
url_from_event: {{url}} 也已经设置好了
我不知道是不是它不支持H5的格式呢?
我要弄的全文xpath里面有section / article 这样的tag, 然后最后是抓取到的东西是包含在一个div里面的,
e.g.
xpath: /html/body/section/div/div[2]/article/div
value: .
div里面就是全文的html,不过dry run 之后还是没有结果返回,2018年1月9日 18:06-
好像是website agent里面有两个url , 重复了
2018年1月9日 19:39-
嗯,多试验几次就可以看到结果了。
2018年1月9日 21:00
-
-
-

你好,我已经配置好,抓取其它网站输出全文是正常了。用huginn有其它办法可以继续爬公众号麽?
2018年1月9日 16:43-
目前用搜狐微信搜索可以抓取微信的前几篇文章,还有一个微信公众号聚合平台倒是可以,搜狐微信有反爬虫策略,量大的话会被发现。
2018年1月9日 21:09
-
-

然后执行脚本 huginn.sh,命令:bash huginn.sh。执行完毕之后,进行如下操作即可:
你好,这一步可以详细点说明下在哪里执行吗
2018年1月8日 20:25-
是Heroku 的命令工具中操作,在线的。
2018年1月9日 08:40
-
-
什么都没有改动过,突然间就出错了, herokuapp 页面显示的 Application error。请问你有遇到过这种情况吗?
2017年12月24日 23:16-
应该是运行时间已经超过了550个小时,请问如何”让网站每天只运行18小时”,在uptimerobot上设置吗?
2017年12月24日 23:23-
那只能是暂时关闭应用了,然后再开启了。
2017年12月25日 13:30-
所以只能人手每天去关闭一下应用再重启吗?
另外,请问一下,有什么将huginn 部署到vps的教程呢?谢谢2018年1月14日 10:15-
1、只能手动停止了。2、有的,手动安装:https://wzfou.com/huginn/。
2018年1月14日 20:55-
大概看了一下, 好像需要配置比较好一点的vps主机, 才可以部署huginn啊, 有什么推荐吗?
2018年1月18日 18:15-
Linode的VPS性价比不错,适合跑这类的应用。
2018年1月21日 20:06-
好的,谢谢. 我之前买的BWG VPS 被*了, ping不通 %也连接不上, 这个Linode会不会也这样呢?
2018年1月24日 10:29-
Linode相对于搬来说价格要贵一些,滥用的少一些,QQ的机会要小一些。另外,被QQ了可以通过更换机房的方式来更换IP。
2018年1月24日 14:10
-
-
-
-
-
-
-
-
-

看一遍又一遍 真心感觉老大写的就是经典啊!!!真心好用 哈哈
2017年12月24日 20:16-
哈哈,我也正在用。
2017年12月25日 13:31
-
-

vps 和 huginn 装好了,phantomjscloud的API Key也配上去了,下了个”微信公众号”改了配置,但跑出来是空值
2017年12月3日 18:00-
我研究了一下是腾讯搜狗那边限制了Huginn这类的爬虫。
2017年12月4日 09:29-

意思是,现在没办法避开反爬虫的问题么?我也是返回空
2017年12月28日 22:41-
是的,除非自己写爬虫。
2017年12月29日 21:42
-
-
-
-
你好啊,我有一个问题想请教一下.
“由于我们用的是自动安装,所以没有创建管理员用户”.
那用什么账号可以登录Huginn instance呢? 试过Heroku的账号是不行的2017年11月23日 13:41-
用这个默认的:账号是:admin,密码是:password。
2017年11月24日 09:56-
请问,如何抓取需要登录的网站数据呢?比如,instagram. 谢谢
2017年12月13日 17:41-
需要登录的网站应该不行,要不然网站的数据都可能被人窃取了。
2017年12月13日 20:01
-
-
-
-

感谢作者,可是导入后微信公众号 #2 获取文章列表 Details 就运行不起来了哎。。
2017年11月19日 13:00-
可以用可以用 原来要注册下phantomjscloud
再次感谢2017年11月19日 13:25
-
-

感谢Qi大,这篇文章得好好研究了,感觉功能很实用~另外是否可以出个打包整站的教程?期待ing
2017年9月15日 06:26-
正在测试当中,Huginn手动安装确实麻烦。
2017年9月15日 08:43-
Qi大是否有推荐的win整站打包软件?现在科#*学#*上##*网形势越来越严峻,看到好文章好网站想全部打包,以防来不及学习就无法访问了
2017年9月15日 09:15-
试试HTTrack,非常强大。
2017年9月15日 22:30
-
-
-
-

再hero#ku上搭建似乎内存不够..抓不到文章列表..
2017年9月8日 14:24-
任务设置少一些就好了。
2017年9月8日 15:49
-
-

最讨厌某些移动 app,特别是 UC,假装懂你的带浏览器功能的新闻客户端
2017年9月1日 20:46-
小米手机的广告更恶心了。。。
2017年9月2日 13:38-
便宜的代价
2017年9月2日 21:42 -

突然觉得好惋惜,那么好的金立被我玩机玩坏了
2017年9月15日 22:02-
变砖了?
2017年9月17日 12:39-
root之后系统升级不了了
2017年9月17日 15:56-
想要玩机当然选一加(OnePlus),性价比高,他们的手机在 XDA Developers 论坛非常受欢迎。其他手机厂家设置了不少障碍,并且不开放 device 树的源代码,也没有诸如 Lineage OS 这样的第三方 Android 系统的官方适配。
当然,说实话我觉得手机真的没啥好玩的,感觉有点浪费时间,我也折腾 Android 一段时间了,现在不再折腾了,保持官方固件并且无 root,享受厂家的服务。现在我偏向选择国际大厂的为中国大陆网络和应用环境做了优化的 Android 手机,比如三星、华为、HTC 等。2017年9月17日 16:55
-
-
-
-
-
-
对于商人而言,RSS 主要无利可图,所以不太受欢迎。不过不知道从哪里看到一句话——“支持 RSS 是一种美德”。
2017年9月1日 20:44-
哈哈,自古以来都是这样。 😀
2017年9月7日 01:31
-
-

收藏一下,以前有看过,但是不知道如何用。
2017年9月1日 16:42 -

好繁琐
2017年8月30日 22:37-

感觉配置有些难度…
2017年9月1日 15:59-
是有点复杂。
2017年9月1日 16:41
-
-
-

这玩意儿其实就是个爬虫
就是弄的插件化了
自己去gihub扒一下一大堆2017年8月30日 22:36-
有点类似,门槛稍微降低了一些。
2017年8月31日 09:26 -

求推荐几个啊,最好是通用一点的语言的,如PHP,PYTHON等。
2017年8月31日 20:22
-
-

可以试试https://perma.cc/,看看怎么样,能不能出个教程,感觉后续开发可以当做Evernote或者OneNote的网页裁剪功能
2017年8月30日 21:56-
确实可以,也可以当成一个存档工具。
2017年8月31日 09:37-

求出教程。这个工具只能每月存5条,真心太少了
2017年8月31日 13:06-
我也是第一次知道,我来看看,貌似自建的话要好一些。
2017年8月31日 17:55
-
-
-
测试成功! Thanks